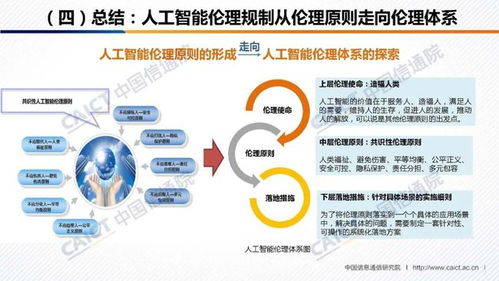
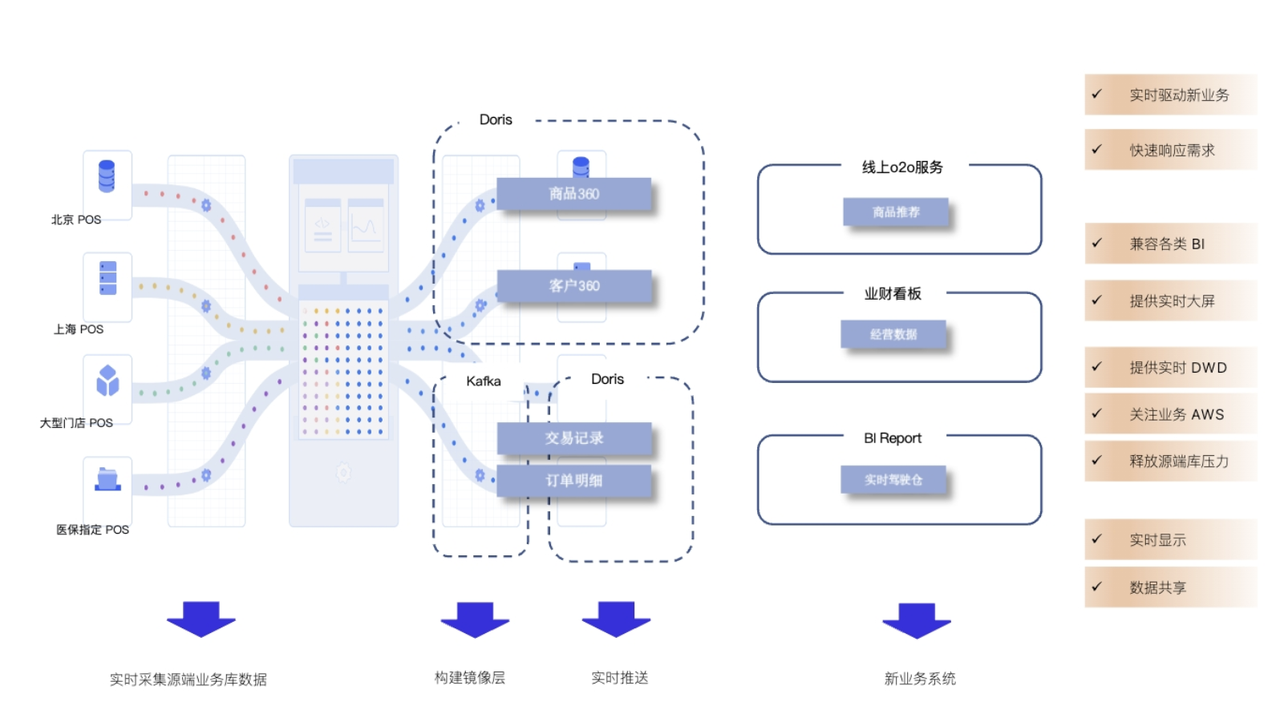
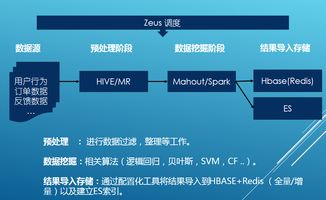
基于Hadoop平臺的電信客服數據處理與分析系統 數據處理服務助你突破畢設難關
對于許多計算機科學與技術專業的學生來說,大數據畢設是一項挑戰,尤其是基于Hadoop平臺的電信客服數據處理與分析系統。如果你正為此苦惱,不必慌張,本文將指導你如何構建一個完整的系統,重點關注數據處理服務,幫助你順利完成任務。
問題背景與挑戰
大數據畢設通常要求處理海量數據,而電信客服數據具有高維度、實時性強和多樣性等特點。常見的難點包括:數據清洗困難、Hadoop平臺配置復雜、性能優化不足以及缺乏實際應用場景。這些因素可能導致學生無從下手,影響畢設進度。
解決方案:構建基于Hadoop的電信客服數據處理與分析系統
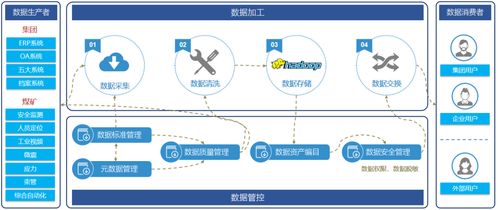
本系統以Hadoop生態系統為核心,結合MapReduce、Hive和Spark等工具,實現客服數據的采集、存儲、處理和分析。以下是關鍵步驟:
- 系統架構設計:采用分層架構,包括數據采集層(如Flume或Kafka)、數據存儲層(HDFS)、數據處理層(MapReduce/Spark)和數據分析層(Hive/可視化工具)。這確保了系統的擴展性和高效性。
- 數據處理服務詳解:
- 數據采集與清洗:使用Flume從電信客服日志中收集數據,并通過MapReduce或Spark進行預處理,去除噪音、處理缺失值,并轉換為結構化格式。例如,可以過濾無效呼叫記錄,確保數據質量。
- 數據存儲與管理:將清洗后的數據存儲在HDFS中,利用Hive建立數據倉庫,便于后續查詢。Hive的SQL-like語法簡化了復雜查詢,適合學生快速上手。
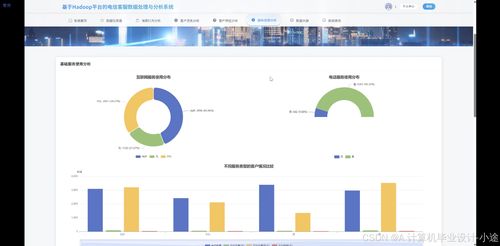
- 數據分析與挖掘:通過Spark MLlib或MapReduce實現關鍵分析,如呼叫量趨勢、客戶滿意度分析和異常檢測。舉例來說,你可以計算高峰時段的客服負載,為電信公司優化資源提供依據。
- 性能優化:調整Hadoop配置參數(如塊大小和副本數),使用壓縮技術減少存儲開銷,并通過并行處理提升速度。這能幫助你在畢設中展示系統的高效性。
- 實踐建議與工具推薦:
- 使用Cloudera或Hortonworks發行版簡化Hadoop部署。
- 結合Python或Java編寫MapReduce程序,利用開源數據集(如電信行業公開數據)進行測試。
- 關注數據處理服務的實時性,例如集成Storm或Flink處理流數據,以增強系統實用性。
突破難關的技巧
- 分階段實施:先從數據采集和清洗入手,逐步擴展到復雜分析,避免一次性處理所有問題。
- 求助資源:參考Apache官方文檔、在線教程(如Coursera的大數據課程)和開源項目,加入社區論壇獲取幫助。
- 測試與迭代:在虛擬環境中反復測試,使用日志分析工具監控性能,確保系統穩定。
通過上述方法,你可以構建一個功能完整的電信客服數據處理與分析系統。這不僅幫助完成畢設,還能提升實際技能,為未來職業發展打下基礎。記住,數據處理服務是核心,專注于它,你就能突破難關!
如若轉載,請注明出處:http://m.guuzn.com/product/15.html
更新時間:2026-02-24 13:07:38