向量、稀疏向量與張量 構建最佳RAG系統的數據處理服務實踐
在當今信息爆炸的時代,全文搜索技術已成為我們獲取信息的重要途徑。隨著數據量的激增和用戶需求的多樣化,傳統的全文搜索已難以滿足高精度、智能化的檢索需求。正是在這樣的背景下,以向量、稀疏向量和張量為代表的新一代檢索技術,結合檢索增強生成(RAG)框架,正在重新定義數據處理服務的未來。
全文搜索的演進:從關鍵詞到語義理解
傳統全文搜索依賴于精確的關鍵詞匹配,雖然速度快,但缺乏對語義的理解,無法處理同義詞、多義詞或復雜查詢意圖。例如,搜索“蘋果”可能返回水果、科技公司或電影等多種結果,而傳統技術難以區分。
向量化表示:開啟語義搜索新篇章
向量技術的引入徹底改變了這一局面。通過將文本、圖像或其他數據轉換為高維空間中的向量表示,我們能夠捕捉數據的深層次語義特征。在向量空間中,語義相似的文檔會聚集在一起,即使它們沒有共享相同的關鍵詞。這種能力使得搜索系統能夠理解“貓”和“貓咪”之間的關聯,或者識別“高興”和“愉快”的情感相似性。
稀疏向量與稠密向量的協同
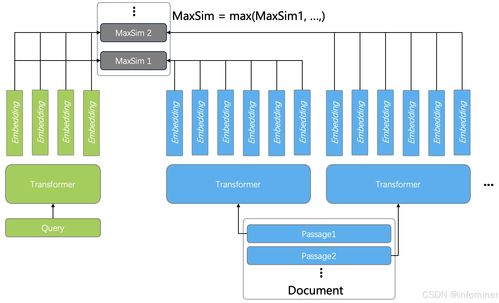
在向量搜索領域,存在兩種主要類型:稀疏向量和稠密向量。稀疏向量通常基于詞頻統計(如TF-IDF),維度高但大部分元素為零,適合處理明確的關鍵詞匹配場景。稠密向量則通過深度學習模型(如BERT、GPT)生成,維度較低但每個元素都包含信息,擅長捕捉語義關系。
最佳實踐表明,將稀疏向量與稠密向量結合使用——即混合搜索——能夠兼顧精確匹配和語義理解,顯著提升檢索效果。稀疏向量確保關鍵術語不被遺漏,而稠密向量則拓展了搜索的語義邊界。
張量:多維數據處理的高級抽象
當數據變得更加復雜,涉及多個維度或模態時,張量成為更合適的數據結構。張量可以看作是向量的高維推廣,能夠統一表示文本、圖像、音頻、視頻及其關聯關系。在多媒體檢索、知識圖譜等場景中,張量運算為復雜查詢和推理提供了數學基礎。
RAG框架:檢索與生成的完美融合
檢索增強生成(RAG)框架將高效檢索與強大生成能力相結合,成為當前最受關注的人工智能應用范式之一。RAG系統首先從大規模知識庫中檢索相關文檔,然后基于這些文檔生成準確、可靠的回答。這種架構既保證了信息的時效性和準確性,又發揮了大型語言模型的推理和表達能力。
構建最佳RAG系統的數據處理服務關鍵要素
- 多向量索引策略:同時維護稀疏向量索引(用于關鍵詞召回)和稠密向量索引(用于語義召回),并根據查詢類型動態調整權重。
- 分層檢索架構:先使用輕量級方法快速篩選候選集,再應用精細模型進行重排序,平衡精度與效率。
- 張量融合技術:對于多模態數據,使用張量分解和融合方法提取跨模態特征,實現統一檢索。
- 實時更新機制:設計增量索引更新管道,確保新數據能夠及時進入檢索系統,保持信息新鮮度。
- 查詢理解與優化:對用戶查詢進行意圖識別、查詢擴展和向量化,提升檢索針對性。
- 評估與迭代:建立全面的評估體系,包括召回率、準確率、延遲等指標,持續優化系統性能。
實際應用場景
- 智能客服系統:結合用戶問題向量化和知識庫檢索,生成準確、個性化的回答。
- 學術研究平臺:通過語義搜索幫助研究者發現相關文獻,即使這些文獻使用不同的術語表述。
- 電子商務推薦:基于用戶歷史行為和商品向量表示,實現“搜索即推薦”的智能購物體驗。
- 企業知識管理:快速定位分散在文檔、郵件、聊天記錄中的相關信息,提高決策效率。
未來展望
隨著硬件算力的提升和算法的不斷優化,向量、稀疏向量和張量技術將在數據處理服務中扮演越來越重要的角色。下一代RAG系統可能會集成更多模態的感知能力,實現真正意義上的多模態理解和生成。聯邦學習、差分隱私等技術的引入,將使這些強大能力在保護數據隱私的前提下得以廣泛應用。
向量、稀疏向量和張量不僅是理論概念,更是構建智能數據處理服務的基石。當它們與RAG框架巧妙結合時,我們能夠打造出既理解語義又保持精確,既高效檢索又智能生成的新一代信息系統,最終為用戶帶來前所未有的信息獲取體驗。
如若轉載,請注明出處:http://m.guuzn.com/product/49.html
更新時間:2026-02-24 12:40:11