分布式協調服務ZooKeeper與數據處理服務的理論與實踐
隨著大數據技術的快速發展,分布式系統已成為處理海量數據的核心架構。在眾多分布式技術中,ZooKeeper作為分布式協調服務的關鍵組件,與數據處理服務緊密協作,為大規模數據應用提供了可靠的保障。本文將結合理論與實踐,探討ZooKeeper在分布式環境中的作用及其與數據處理服務的關系。
一、ZooKeeper的核心概念與功能
ZooKeeper是一個開源的分布式協調服務,由Apache基金會維護。它通過簡單的數據模型和高效的協議,為分布式應用提供一致性、可靠性和協調能力。其核心功能包括:
- 配置管理:集中存儲和管理分布式系統的配置信息,實現動態更新。
- 命名服務:提供分布式系統中的節點注冊與發現機制。
- 分布式鎖:支持互斥鎖和讀寫鎖,確保資源訪問的互斥性。
- 集群管理:監控節點狀態,實現故障檢測和主節點選舉。
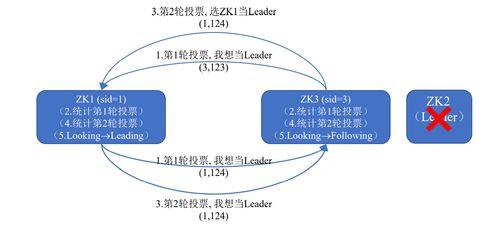
在實踐層面,ZooKeeper采用樹形數據模型(ZNode),每個節點可存儲少量數據(通常不超過1MB),并通過ZAB(ZooKeeper Atomic Broadcast)協議保證數據一致性。例如,在Hadoop生態中,ZooKeeper被用于HBase的主節點選舉和RegionServer狀態管理。
二、ZooKeeper與數據處理服務的協同機制
數據處理服務(如Apache Kafka、Apache Flink等)依賴ZooKeeper實現分布式協調。具體協同方式包括:
- 元數據管理:ZooKeeper存儲數據分片、任務分配等元數據,確保處理節點間信息同步。
- 故障恢復:通過臨時節點監控處理節點存活狀態,實現自動故障轉移。
- 流量控制:協調數據生產者與消費者的速率,避免系統過載。
以Kafka為例,其依賴ZooKeeper管理Broker注冊、主題分區信息和消費者偏移量。當Broker故障時,ZooKeeper會觸發重平衡機制,重新分配分區至健康節點。
三、實踐案例與優化策略
在實際部署中,需關注ZooKeeper的性能與可靠性:
- 集群部署:建議采用奇數個節點(如3或5)組成集群,通過多數投票機制避免腦裂問題。
- 數據持久化:配置合理的快照與事務日志清理策略,防止磁盤溢出。
- 監控告警:通過四字命令(如stat、ruok)或JMX接口實時監控集群狀態。
對于高并發場景,可通過以下方式優化:
- 減少Watcher數量:避免過多監聽器導致性能下降。
- 使用Curator框架:簡化ZooKeeper客戶端編程,提供重試、緩存等高級功能。
四、未來發展趨勢
隨著云原生技術普及,Etcd、Consul等新興協調服務逐漸興起,但ZooKeeper在成熟度和生態集成方面仍具優勢。ZooKeeper將更多與容器化、服務網格技術結合,為數據處理服務提供更輕量級的協調方案。
ZooKeeper作為分布式系統的“基石”,通過與數據處理服務的深度集成,確保了大數據應用的可靠運行。開發者需深入理解其原理,并結合實際場景設計合理的架構,方能充分發揮分布式系統的潛力。
如若轉載,請注明出處:http://m.guuzn.com/product/37.html
更新時間:2026-02-24 10:20:36